You are surely aware of prompting a Large Language Model to get the output you want, and you probably know about RAG, few-shot, and CoT (if not, read my explainer). But although you might hear that prompting is the only game in town, there are actually several other techniques beyond prompting that you can use to influence LLM output.
From easiest to hardest, they are:
- Prompt
- Samplers
- Change sampler params
- Constrain grammar
- Switch samplers
- Run-time feature modification
- Representation Engineering (RepE)
- Sparse AutoEncoder (SAE)
- Distillation
- Quantize
- Prune
- Fine-tuning
- Low-Rank Adaptation (LoRA)
- Other fine-tuning methods
Samplers
Since I already wrote about prompting techniques, let’s skip RAG, chain-of-thought, few-shot, and everything that can go into prompting. Let’s focus first on modifying the token sampler.
Sampler parameters
Did you know that an output from a transformer model is not one token (a token is a word or word fragment), but many tokens? The model gives each word a probability that it should come next. It is up to the sampler to pick from this list. When you interact with a chatbot, it continuously picks a word from those lists based on its sampler implementation.
The most obvious way to pick the next word is to always take the one with the highest probability. You can do this in many LLM APIs by setting the Temperature to 0.0. This turns out to usually not be the best approach, because the output is very basic and uncreative. Setting the Temperature to 1.0 causes the output to get pretty wacky.
Sometimes you can also set the number of tokens to choose from, with Top-k or Top-p. Lower values restrict the words that can be chosen, with similar effects to a lower temperature. It’s rare to see the option to change sampler parameters in a chat interface, but most programmatic APIs support it.
Constrain grammar
There’s a great trick that you can do within a sampler to only allow selection from a few tokens. In HTML, after a left angle-bracket (<), there are only a few dozen next words that are valid, like “p”, “span”, and “div”. There’s no sense in letting the sampler pick “pineapple” because that wouldn’t be valid HTML. OpenAI’s Structured Outputs work in exactly this way, forcing JSON syntax output from your API call.
Change samplers
Changing the sampler entirely to use your own logic is a little bit more exotic. There are a couple samplers out there that support more complicated logic, like Min-P and Entropix. These work by changing the sampling logic based on what the distribution of probabilities of next tokens look like.
This method is going to be a lot of work if you are calling an LLM API. You could do it with an API that supports returning the logprobs property. You would have the API output only one token, process the logprobs according to your own sampler, add it to the conversation, and call the API again. This would be hideously inefficient! You would pay for all the conversation history input tokens hundreds of times more often than having the API return a few hundred tokens for a complete response.
Unfortunately, if you’re using someone else’s model and don’t have the model weights yourself, this is where you have to stop. But if you do have access to the model weights, there’s a lot more you can do to change the output.
Change the model weights at runtime
An LLM is made up of billions and billions of “weights,” which is just a fancy word for “numbers” in this context. What each number means is usually uninterpretable, but there are some techniques that allow you to usefully change them anyway.
Representation Engineering
The basic idea of Representation Engineering (RepE) is to “watch” what neurons activate while the LLM is producing output with a certain characteristic, e.g. an angry tirade. Then later, you can boost (or suppress) those neurons for future output. An example result is unreasonably angry output when asked a peaceful question. More practically, you can encourage the model to output very factual and terse output, or in any other stye, more reliably than through prompting. I wrote a whole post on RepE, and also made a web demo on Hugging Face.
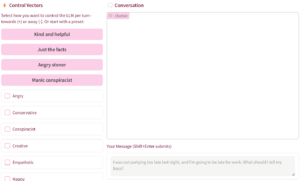
Boosting weights very much tends to break the model — it will start producing gibberish or repeating a short phrase continuously.
Sparse Autoencoder
Anthropic trained a Sparse Autoencoder (SAE) to identify features of their model, each composed of groups of neurons. Then, like RepE, they manipulated the model weights that corresponded to a topic. For Golden Gate Claude, they forced the neurons that corresponded to the Golden Gate bridge to always activate, with hilarious results.
There are undoubtedly other mechanisms to identify and modify features of a model, but the SAE approach and term seems to be catching on.
Distillation
Both quantization and pruning are mechanisms to reduce the model size, so that it is faster or cheaper to run. Output is necessarily worse, although sometimes not much so.
Quantization works by changing the model weights from being stored in (for example) 32 bits to 8 bits. The math is more complicated than this, but you could imagine multiplying 0.872 by 256 and then rounding to the nearest integer, 223. 223 can be stored in 8 bits, while 0.872 requires 32 bits.
The idea behind pruning is to remove any model weights that are close to 0, because they won’t affect the output very much. But because of how the math works in matrix multiplication, it turns out that you must remove quite a bit of information before pruning is effective.
Fine-tuning
Fine-tuning is taking an existing model and continuing to train it to permanently change its weights. There are many approaches and reasons to fine-tune.
Low-Rank Adaptation
More commonly called LoRA, Low-Rank adaptation is an efficient method of fine-tuning. Instead of changing every model weight, a LoRA approximates the model and makes changes to the approximation. Because it is an approximation, the LoRA can be quite small relative to the model. A great use for this is to train multiple LoRAs for different tasks, then swap them in and out for the task currently at hand. This is much easier than training separate models for every task you need the AI to do.
LoRAs are very popular in open-weight image generation. Civit.ai is a catalog of thousands of LoRAs, representing celebrities, styles, or concepts. You can mix-and match these to get the perfect image. It seems rare to use them with LLMs — my hypothesis is that it is relatively easy to describe the style of text that you want and relatively difficult to describe the precise style of image you want. It may be easier to find a few examples of the image style and train a LoRA.
Other fine-tuning approaches
I’m aware of a few other shortcuts so you don’t need to change every parameter of a giant LLM, such as training a hypernetwork or inserting adapter layers. Without these shortcuts, it is a full backpropagation, millions of times. Fine-tuning is extremely important in LLM post-training, which can convert what amounts to a completion engine into an instruct model that we are used to. The major breakthrough immediately behind ChatGPT was this fine-tuning of the base GPT-3 into a chat/instruct model.
But exactly when to use which fine-tuning approach, choosing a mechanism (e.g. RLHF or DPO), and setting a reward function is the realm of data science and not product management or even AI engineering. I’m not qualified to help you with that.
Beyond Prompting
If you’re an AI engineer, or even just an engineer that uses an AI in your software, I hope this gives you a push to move beyond prompting. You can use so many other techniques to get the outputs you want, more reliably, and often cheaper. As you experiment with these approaches, don’t forget to run your evals!