Previous post | All posts in series | Next post
My goal today is to add semantic search capabilities to The Archive. The Archive currently uses a lexical search (matching words in the user’s search with words in the article) based on search terms generated by the LLM. A semantic search will match what the user’s phrase means with phrases that mean similar things in the database. Semantic search should be able to get a much better subset of data into the model’s context window. I’m very curious how semantic search will compare to LLM+lexical.
On the face of it, semantic search is very simple:
- Generate a vector, e.g. a 768-tuple, that represents each document in the database
- Generate a vector of the search query in the same way
- Calculate the distance between the input vector and vectors in the database index
In practice, it’s more complicated than this theory. I’ll need to select an embedding model, re-process Wikipedia into vectors, load it into a database that supports vector similarity search, and decide how to combine it with the existing search. I’m currently at commit 7f77eb2 as I write this. Follow along!
Approach investigation
The Pinecone vector database seems to get the most attention in LLM development, but it isn’t local. I think most folks use Chroma for local execution. However, Chroma loads all the vectors into memory, calculated as:
number of rows * dimensionality (e.g. 768) * 4 bytes = memory requirement in bytesThe Wikipedia English dataset has 6.2M rows. But it’s worse than that, because having the semantic embedding of an entire Wikipedia article is not very helpful. Embeddings are generally per-sentence and no larger than per-paragraph. Even if I use per-paragraph embeddings, assuming 10 paragraphs per article, we get 190GB of needed memory. No way will that work on most PCs, let alone a future phone or hardware device. Let’s try something else.
The good news is that basic Elasticsearch now supports vector similarity search. ES keeps its index on disk, and it is extremely configurable. I suspect that if it won’t work out-of-the-box, I’ll still be able to make it work. Let’s find out!
Calculating embeddings
I first checked whether anyone had done this work for me. Somehow, no one1 has ever calculated embeddings for all English Wikipedia, although there are lots for Simple English Wikipedia.
Huggingface maintains a leaderboard of embedding models evaluated by MTEB (Massive Text Embedding Benchmark). I’m looking for a model that has low memory requirements and scores well. I also don’t want to have too many embedding dimensions, as it would make my database size explode. Later, it may be worth evaluating multiple models on my actual data and queries, but setting up an eval pipeline will come later. For now, I’m picking the GIST-small-embedding-v0 model. It scores in the top 50 on MTEB, only needs 123 MB of memory, and only uses 384 dimensions. I’m also using some wisdom of the crowds, as this model has more downloads than similar models.
My first implementation of calculating embeddings with langchain_community.embeddings.llamacpp was only able to calculate about one article per second on my PC. 6.2M million seconds would 71 days, so that’s not going to work. I improved this a little bit by adding parallelization, but not enough. I switched to Sentence-Transformers (SBERT) from Huggingface and immediately saw a 4x speed increase. I noticed that I was using very little of my GPU memory with the default batch size of 32, and so I tried various batch sizes until my GPU memory and CPU were both nearly maxed out. This turned out to be batches of 700 articles (remember each record contains many paragraphs). This let me process 1400 articles in a little over 2 minutes. Calculating embeddings for all English Wikipedia would then take 6-7 days.
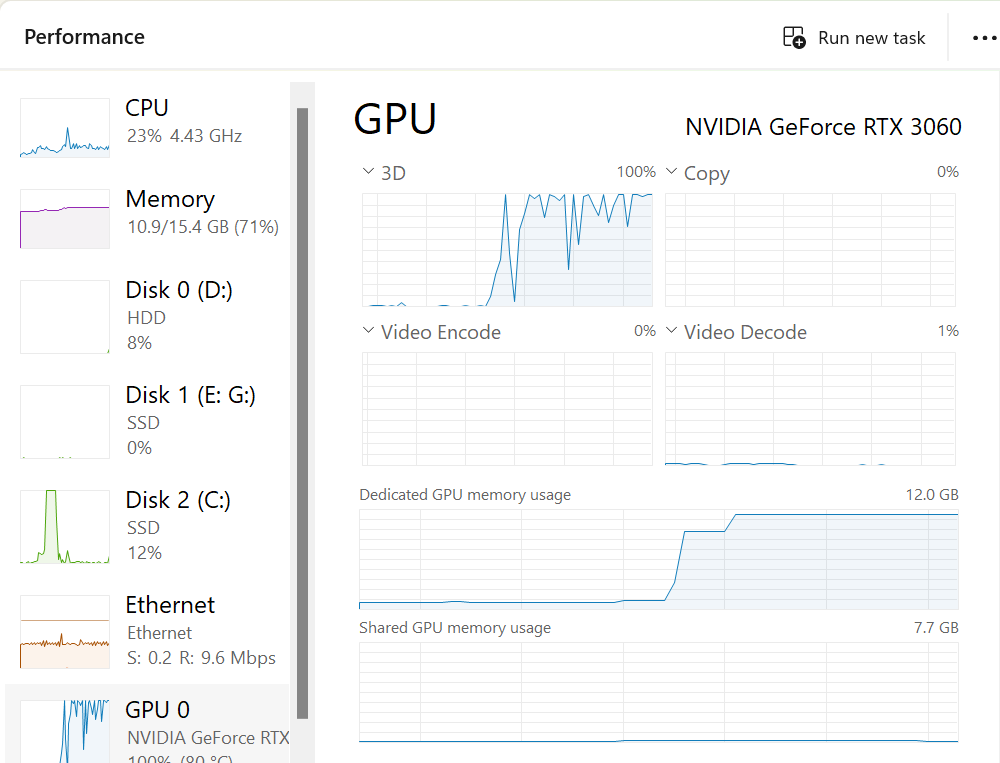
This still isn’t fast enough for me, so I rented a container with an Nvidia A40 from RunPod. Maxing out this GPU brought the processing time down to 20 hours, costing me $7. Keeping in mind that a lot of this database will need to be in memory even with Elasticsearch, I also quantized it to int8. Each paragraph embedding is then 384 bytes.
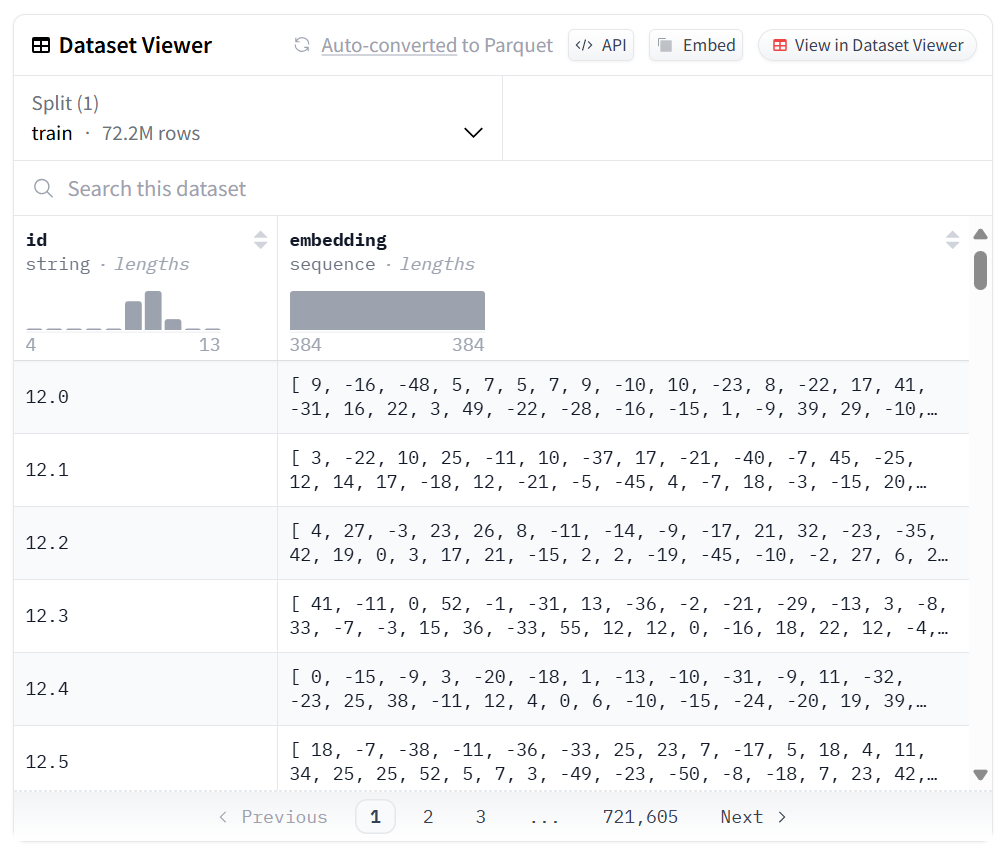
Now someone has calculated embeddings for all English Wikipedia: me! You can download it yourself from Huggingface 🤗 at Abrak/wikipedia-paragraph-embeddings-en-gist-complete. It ended up at 72 million rows and 29 GB. This actually could fit into system memory on a large desktop computer, but I’m glad I’ve been optimizing.
Coming up
I have the embeddings, but they’re not searchable yet. From my tests, I know Elasticsearch KNN (k nearest neighbor) works on small subsets of the data. I also know that adding the embeddings to an index is a slow process; I’ll need more parallelization and to rent a memory-heavy server. I’m confident there’ll be even more problems scaling up.
The Archive application LLM also has to use the vector search, and so setting that up will follow. It’s also time to set up an evaluation suite. There is lots to do, but this is very fun work!
- Cohere has calculated similar embeddings for all Wikipedia, but the model they used is private. It can only be used online with their paid API. ↩︎